อัลกอริทึมที่ประมาณค่าได้แปรผันกับข้อมูลนำเข้า
ปัญหาทางการคำนวณหลายปัญหามีความยากขั้น NP ซึ่งหมายความว่าเราไม่สามารถหาอัลกอริทึมที่เร็วพอเพื่อแก้ปัญหาเหล่านั้นได้ ทางออกหนึ่งก็คือเลิกคิดถึงอัลกอริทึมเพื่อหาคำตอบที่ดีที่สุด แล้วเปลี่ยนไปคิดอัลกอริทึมที่ไม่ช้าจนเกินไปแม้จะได้คำตอบเป็นค่าประมาณก็ตาม
ถ้าเราพิสูจน์ได้ว่าอัลกอริทึมแบบประมาณนั้น ให้ที่คำตอบไม่แย่ไปกว่า 2 เท่าของคำตอบที่ดีที่สุด (สำหรับทุกๆ ความเป็นไปได้ของข้อมูลนำเข้า) อัลกอริทึมดังกล่าวจะเป็นแบบ 2-approximation สังเกตว่าเลข 2 นี่เป็นค่าคงที่และไม่ขึ้นกับขนาดของข้อมูลนำเข้า
แต่ก็ยังมีอัลกอริทึมประมาณอีกประเภท ที่ไม่สามารถประมาณคำตอบเป็นค่าคงที่ของคำตอบที่ดีที่สุด บทความนี้จะใช้ปัญหาการปกคลุมเซตเป็นตัวอย่าง
ปัญหาการปกคลุมเซต (set cover problem) ให้ข้อมูลนำเข้าเป็นเซต
ตัวอย่างเช่น
แผนภาพออยเลอร์ของเซตตัวอย่างข้างต้น
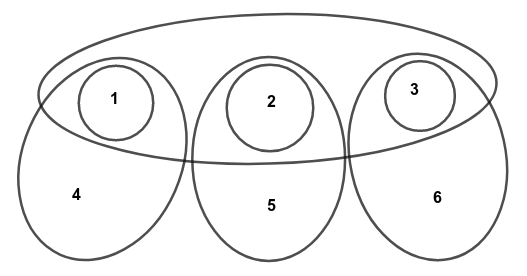
อัลกอริทึมประมาณค่าที่ทำงานแบบละโมบ จะเลือกหยิบ
จากตัวอย่างข้างต้นแต่เปลี่ยนมาใช้อัลกอริทึมแบบละโมบ จะได้ว่ารอบแรกเราเลือกหยิบ
แล้วคำตอบแบบประมาณที่ได้จากอัลกอริทึมนี้ต่อข้อมูลนำเข้าใดๆ มีสัดส่วนเป็นเท่าไหร่หละ? หากลองสร้างตัวอย่างอื่นมาดูเรื่อยๆ จะพบว่าค่าประมาณนั้นไม่ได้เป็นจำนวนเท่าแบบค่าคงที่เลย
วิธีหาสัดส่วนค่าประมาณของอัลกอริทึมนี้ เริ่มด้วยการสมมติก่อนว่าคำตอบที่ดีที่สุดมีขนาดเป็น
ในรอบที่สอง เซตที่ถูกเลือกจะมีขนาดอย่างน้อย
หลังจากอัลกอริทึมทำงานไป
นั่นหมายความว่าอัลกอริทึมแบบละโมบจะทำงานอย่างมากสุดแค่

author