ปัญหาการจ้างเลขาและค่า
ลองจินตนาการว่าเรากำลังจะเปิดบริษัทแต่ยังขาดพนักงานเลขา ซึ่งตำแหน่งดังกล่าวถือว่าเป็นตำแหน่งฮอตฮิตที่บริษัทไหนๆ ก็ต่างแย่งชิงตัว การเรียกผู้สมัครมาสัมภาษณ์งานจึงจำเป็นต้องตอบรับทันทีเดี๋ยวนั้น มิเช่นนั้นแล้วก็รับประกันได้เลยว่าผู้สมัครจะถูกบริษัทอื่นแย่งตัวไปในทันทีที่เขาก้าวเท้าออกจากออฟฟิศ
สมมติว่าเราสามารถเรียกผู้สมัครมาสัมภาษณ์ได้มากที่สุด
มองเผินๆ นี่อาจจะดูเหมือนปัญหาที่ไม่น่าเป็นไปได้ ในเมื่อเราไม่รู้ว่าใครดีกว่าใครจนกว่าจะได้สัมภาษณ์ แต่พอสัมภาษณ์เสร็จก็ต้องตอบรับว่าจะให้ร่วมทางกับบริษัทเราหรือไม่ซะแล้ว หากเราถอดใจไม่วางแผนใดๆ และเลือกตอบรับผู้สมัครแบบสุ่ม โอกาสที่จะได้ผู้สมัครที่ดีที่สุดก็จะมีเพียงแค่
แต่เนื่องจากเราสามารถเปรียบเทียบผู้สมัครได้ หากเราลองสัมภาษณ์ผู้สมัครคนแรกดูก่อน (และต้องแข็งใจบอกปฏิเสธไป) เพื่อเป็นบรรทัดฐานว่าเราอยากได้ผู้สมัครประมาณไหน เมื่อสัมภาษณ์ต่อไปและพบว่าผู้สมัครคนที่สองดีกว่าคนแรก อย่างน้อยโอกาสที่เขาจะเป็นผู้สมัครที่ดีที่สุดก็มีมากกว่าการสุ่มแน่ๆ
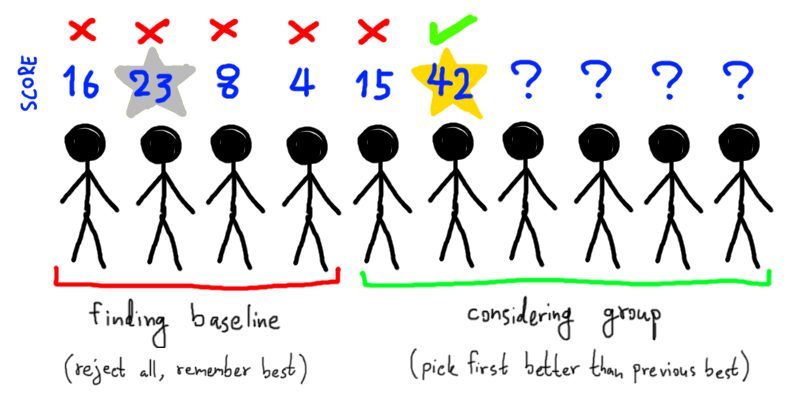
หากเราแบ่งการสัมภาษณ์ออกเป็น 2 ช่วง โดยช่วงแรกสัมภาษณ์ผู้สมัครเป็นสัดส่วน
โดยที่
ซึ่งเราจะเห็นว่า
หาก
ให้
ซึ่งเราสามารถใช้อนุกรมเทย์เลอร์มาช่วยแก้ได้ โดยเทคนิคคือเลือกใช้ฟังก์ชันที่อนุพันธ์อันดับ
เลือกกระจาย
ดังนั้น
แล้วใช้เทคนิคอนุพันธ์จากแคลคูลัสเพื่อหาค่า
ก็จะได้คำตอบว่า สัดส่วนที่เหมาะสมที่สุดที่ควรใช้หาบรรทัดฐานในช่วงแรก คือ
และแนวทางการวิเคราะห์ข้างต้นก็สามารถนำไปใช้หาความน่าจะเป็นที่จะได้ผู้สมัครในอันดับอื่นๆ ได้เช่นกัน ดังตัวอย่างอันดับแรกๆ ดังนี้
จะเห็นว่าด้วยวิธีนี้โอกาสที่จะได้ผู้สมัครที่ดีที่สุดสองอันดับแรกก็กินไปแล้วถึงครึ่งนึง 🤯

author